

Luglio 9, 2021
2138 Views
Il Mercato dei Dati è la prima collana di pubblicazioni targata Privacy Network. È un lavoro nato da una domanda semplice: quanto valgono i dati, oggi? Abbiamo cercato di rispondere attraverso due linee narrative distinte, partendo dalla strategia europea per il mercato digitale.
Con la prima linea narrativa abbiamo approfondito la nuova “data economy”: che valore commerciale hanno i dati, e che valore ha la protezione di questo nuovo asset produttivo? Per rispondere abbiamo affrontato il tema dei dati come input produttivo: dai data broker fino ad arrivare all’industria del cybercrime. Successivamente è stato affrontato il tema parallelo del valore della protezione dei dati in azienda, valutato grazie ad alcuni recenti studi internazionali.
La seconda parte della pubblicazione affronta invece l’aspetto sociale del valore dei dati: che valore danno le persone ai loro dati e alla loro privacy? Grazie a una survey somministrata durante i primi mesi del 2021 abbiamo delineato un quadro realistico della percezione delle persone. Quello che si evince è una generalizzata sfiducia da parte delle persone per il mercato digitale, che si riflette in tentativi di autotutela che dovrebbero essere supportati dalla società civile, dalle istituzioni, e anche dalle imprese.
Data Economy, volti di un nuovo ecosistema
Autore: Dipartimento Ricerca
Da anni ormai si parla di dati, spesso con metafore che richiamano al “nuovo petrolio”, fino ad a paragonarli addirittura alla luce del sole – perché i dati, proprio come i raggi solari, arrivano ovunque.
A prescindere dalle metafore, una cosa è chiara: sempre più aziende utilizzano dati come input produttivo, per ottenere utili insights di business, o per monetizzarli direttamente in qualche modo.
Non è necessario guardare alla big tech per constatare che il digitale vive di dati.
Dalle aziende che vendono beni digitali per il mercato consumer, passando dalle aziende che offrono servizi SaaS business to business, fino ad arrivare alla più moderna telemedicina; i dati sono ovunque.
Questa espansione iperbolica dell’economia data-driven è dovuta in gran parte dalla riduzione del costo di storage dei dati, assieme alle sempre più accessibili tecnologie di acquisizione e analisi di Big Data.
Con Big Data si descrive l’attività di acquisizione, accumulo e analisi in tempo reale di quantità enormi di dati eterogenei tra loro (testo, audio, video, immagini, metadati, e così via).
Questa crescita è la conseguenza diretta della digitalizzazione delle nostre vite. Tutto quello che facciamo, guardiamo, ascoltiamo è digitalizzato. Le nostre relazioni, esperienze, speranze e paure. La nostra vita è la fonte primaria di Big Data.

Nel 2014 il “Working Party 29”, oggi Comitato Europeo per la Protezione dei Dati, rilasciò alcune dichiarazioni sull’impatto che i Big Data avrebbero avuto sull’economia globale.
Il Comitato nutriva grandi speranze, aspettando numerosi benefici collettivi e individuali dallo sviluppo di questa nuova tecnologia, pur sapendo che sarebbe stato necessario un approccio innovativo alla protezione dei dati personali.
Oggi queste tecnologie sono certamente più reali e concrete di quanto lo fossero nel 2014, anche se i benefici collettivi sperati tardano ad arrivare. Probabilmente, a causa del gap tecnologico e culturale che l’Unione Europea deve coprire rispetto a Stati Uniti e Cina.
L’Unione Europea è però consapevole del valore dei dati come fulcro della trasformazione digitale. Proprio per questo, è stata delineata una vera e propria strategia europea in materia di dati e digitale, che mira a fare dell’Unione un leader globale nella società dell’informazione.
Secondo le stime dell’UE il valore dell’economia dei dati passerà dai 301 miliardi del 2018, a 829 miliardi nel 2025.
Questo boom sarà supportato da uno spaventoso aumento del volume di dati trattati, dai 33 zettabytes del 2018 fino ai 175 zettabytes previsti entro il 2025. Pensiamo solo che più del 90% dei dati oggi disponibili al mondo è stato prodotto negli ultimi quattro anni.
La rapidissima crescita di volume dipende in gran parte dalla sempre più crescente diffusione dell’Internet of Things, con un rilevante cambio di paradigma: i dati non sono più esclusivamente acquisiti ed elaborati in modo centralizzato, ma da una miriade di oggetti connessi con capacità di elaborazione direttamente nel momento in cui sono acquisiti i dati.
Per supportare la creazione del mercato unico dei dati, ci sono in programma investimenti fino a 8 miliardi di euro per infrastrutture e servizi.
Il mercato unico dei dati europeo sarà supportato anche da un framework normativo uguale per tutti e adeguato alle sfide del ventunesimo secolo.
Il primo passo per la creazione di questo framework è già stato fatto, con il General Data Protection Regulation (GDPR) – entrato in vigore nel 2016.
Lo scopo del GDPR è quello di creare un contesto di regole comuni per il trattamento dei dati personali, tutelando al tempo stesso i diritti delle persone a cui si riferiscono questi dati.
Lo scopo primario è agevolare la libera circolazione dei dati all’interno dell’Unione Europea, stimolando al tempo stesso la fiducia delle persone nell’economia digitale.
Il GDPR sarà seguito da altri Regolamenti altrettanto importanti:
- Il Regolamento ePrivacy, che detterà le regole per le comunicazioni elettroniche, per il trattamento dei cosiddetti “metadati”, e per l’advertising online
- Il pacchetto digitale, composto da ben tre Regolamenti: Digital Services Act, Digital Markets Act, e Data Governance Act
- Il Regolamento sull’Intelligenza Artificiale, che per la prima volta al mondo cercherà di regolamentare l’uso dell’intelligenza artificiale
La prosperità dell’Unione Europea del prossimo decennio dipenderà in gran parte dalla capacità di posizionarsi a livello globale nella data economy, assicurando la competitività delle imprese e il progresso sociale ed economico.
L’Unione Europea è forte nella sua convinzione che la data economy sia il futuro. Ma che dire invece delle aziende e delle persone che vivono nell’Unione Europea?
Le aziende sono in grado di percepire il valore dei dati? Qual è il loro valore monetario? E che dire poi dei consumatori, veri e propri protagonisti di questo mercato?
Noi abbiamo cercato di rispondere a queste domande, attraverso un percorso logico che si concentra in questa prima parte sul valore di mercato (legale e illegale) dei dati, e poi sul valore della protezione di questi dati in ambito aziendale.
Trattare dati, che significa?
Prima di affrontare il tema del valore di mercato dei dati bisogna capire cosa sono i dati personali e cosa si intende per trattamento di dati personali.
I dati sono informazioni. Queste possono essere scritte su supporti cartacei o elettronici di ogni tipo: sequenze di 0 e 1 – bits elaborati da computer. Non tutte le informazioni sono uguali, però.
Quando queste informazioni si riferiscono a persone identificate o identificabili (i data subjects), allora acquisiscono lo status di dato personale.
I dati personali non sono quindi una classe statica e definita di informazioni, ma un insieme estremamente fluido nel quale ogni tipo di informazione può entrare e uscire, a seconda del contesto e a seconda delle operazioni che vengono realizzate con quelle informazioni.
L’Unione Europea si è dotata già da tempo di una cornice normativa largamente incentrata sul concetto di “dato personale”, che è una vera e propria definizione giuridica.
Lungi dall’essere un esercizio di stile, riuscire a definire e suddividere le informazioni tra dati personali e dati non personali è quindi fondamentale per poterne fare uso nel rispetto delle regole sul trattamento dei dati, sia in Europa che nel resto del mondo.
In alcuni casi è molto semplice riconoscere i dati personali. Ad esempio, le informazioni direttamente identificative come il nome e cognome, l’indirizzo di casa, o il numero di telefono, sono certamente dati personali. Ma ci sono molte altre informazioni che possono acquisire lo status di dato personale nel momento in cui vengono correlate con altre informazioni.
Ad esempio:
- Informazioni generate dalle persone durante l’uso di un servizio digitale
- Informazioni sul comportamento delle persone durante l’uso di un servizio digitale
- Metadati (es. localizzazione, data e orario di una chiamata, ricevute di invio e ricevimento di email)
Quando queste informazioni vengono elaborate e messe insieme ad altre informazioni, creando un contesto in cui diventano riferibili a una persona identificata o identificabile, diventano dati personali.
Definito il concetto di dato personale, vediamo invece cosa si intende per trattamento – una parola a cui molte persone sono ormai abituate a leggere sulle privacy policy ma che forse non rende bene la dimensione pratica dell’attività.
In realtà, è molto semplice: per trattamento si intende qualsiasi operazione fatta su dati personali. Ad esempio, la raccolta di dati con un modulo online è un trattamento. Oppure la strutturazione di dati, in un archivio o in un file. O ancora, l’estrazione, la consultazione o la comunicazione di dati. Perfino la cancellazione è un trattamento.
Il trattamento di dati è quindi l’attività che trasforma le informazioni in patrimonio utilizzabile dalle aziende per prendere decisioni, o per erogare servizi.
Il trattamento di dati personali, però, non è privo di conseguenze.
Ogni volta che un’azienda tratta dati, si creano degli effetti più o meno visibili anche sull’ecosistema che circonda l’azienda, andando ben oltre il limite dei rapporti diretti tra azienda e data subject. Questi effetti possono essere definiti come esternalità, per prendere in prestito un termine della teoria economica. Le esternalità derivanti dal trattamento di dati possono essere positive o negative.
Per un singolo trattamento di dati possono esserci sia esternalità positive che negative. Ad esempio, le persone possono certamente beneficiare dal comunicare i loro dati personali alle aziende con cui si interfacciano, magari per ottenere specifici prodotti e servizi.
Questo processo di acquisizione ed elaborazione di dati espone però le persone anche a esternalità negative, che possono essere di vario tipo: dalle più lievi, come il ricevimento di spam o chiamate di telemarketing aggressive all’ora di cena, fino ad arrivare a discriminazioni negative sui prezzi di beni e servizi. Ad esempio, un’assicurazione sulla vita potrebbe essere più costosa perché l’agenzia assicurativa è in possesso di informazioni riservate sullo stato di salute della persona, magari grazie ad accordi commerciali con FitBit.
È chiaro quindi che il trattamento di dati personali, benché necessario, ha un grande impatto sulla società.
Questo è tanto più vero quando pensiamo al ruolo dei Big Data e dell’intelligenza artificiale nella nostra società. Gli algoritmi di machine learning vivono e si nutrono di dati, e spesso sono motori silenziosi di processi decisionali automatizzati che hanno conseguenze sulla vita di ognuno di noi, e che spesso si propagano ben oltre il rapporto diretto tra la persona e l’algoritmo, causando esternalità che impattano su tutta la società a livello sistemico.
Ogni ambito umano è ormai pieno di decisioni automatizzate prese da algoritmi che influenzano la realtà di milioni di persone ogni giorno: dalla visualizzazione delle informazioni disponibili sul web, alla ricerca di lavoro, fino alla politica, educazione, giustizia, e finanza. Ad esempio, come evidenziato da Cathy O’ Neil nel libro “Weapons of Math Destruction”, l’industria dell’advertising usa specifici algoritmi automatizzati per far visualizzare determinati messaggi pubblicitari alle persone più suscettibili. Non è raro l’uso di keywords come “bassa autostima”, “mamma single con figli”, “gravidanza”, “divorzio recente”, o “lutto recente”.
Il legislatore europeo è consapevole di questo, ed è il motivo per cui la normativa per la protezione dei dati (GDPR) si occupa in prima linea di tutelare le persone dalle esternalità negative che si creano con il trattamento di dati. Nei termini di legge queste esternalità sono definite come “rischi per i diritti e libertà dei soggetti interessati”. Al GDPR si aggiungeranno come detto anche altri Regolamenti, come quello sull’Intelligenza artificiale, che cercherà proprio di mitigare il rischio di esternalità negative derivanti dall’uso di sistemi di intelligenza artificiale.
Purtroppo, non è possibile determinare a priori quale sarà l’impatto di un trattamento di dati personali, automatizzato o meno, e per questo il legislatore rimanda ogni valutazione di merito alla responsabilità individuale delle imprese – la cosiddetta “accountability”, di cui parleremo in seguito.
Dati personali: un mercato dinamico
Non ci sono metodologie universalmente accettate per stimare il valore di mercato dei dati personali, ma nel corso del tempo sono stati individuati alcuni approcci che possono fornire informazioni utili.
Un primo approccio, rivolto principalmente all’ambito aziendale, è quello di considerare e analizzare diversi indicatori di mercato, come:
- I risultati finanziari delle aziende in relazione al volume di dati trattati
- Il prezzo dei dati venduti sul mercato
- Il prezzo dei dati venduti sul mercato illegale
Un altro approccio, che sarà affrontato nella seconda parte di questa pubblicazione, mira invece a valutare direttamente la percezione che le persone hanno dei loro dati, principalmente attraverso survey e interviste, per comprendere il valore che le persone assegnano ai loro dati e per comprendere la disponibilità a pagare per proteggerli.
Entrambi gli approcci hanno pro e contro, e bisogna sempre ricordare che per la loro natura non saranno mai valutazioni pienamente affidabili, anche perché non tengono conto dell’impatto sociale (esternalità positive e negative) del trattamento di dati.
Il rapporto tra risultati finanziari e volume di dati trattati
Un modo per stimare il valore di mercato dei dati personali è quello di esaminare il rapporto diretto tra risultati finanziari e volume di dati trattati dalle aziende.
Questa tipologia di approccio gode del vantaggio utilizzare indicatori facilmente identificabili, con un rapporto che riflette direttamente il valore economico che viene generato attraverso i dati.
Ci sono però alcuni inconvenienti. Il primo, è che questo tipo di analisi funziona soltanto per le aziende data-driven, cioè quelle aziende il cui business model è completamente incentrato sull’acquisizione ed elaborazione di dati, come Google, Facebook, o le aziende che sviluppano modelli di intelligenza artificiale.
Il secondo problema è che i risultati finanziari di un’azienda data-driven avranno una correlazione con il volume di dati trattati, ma non solo. Ci sono molti altri elementi che potrebbero influire sui risultati finanziari, di cui è difficile tener conto: speculazione di mercato, esternalità positive o negative, o altre variabili estranee dai dati o dal modello di business, come il capitale umano. Per questo motivo, questo tipo di analisi rischia comunque di essere inaccurata.
Questa metodologia è comunque un buon punto di partenza per stimare il livello di “produttività” dei dati, perché è possibile assegnare un valore monetario diretto ai dati trattati.
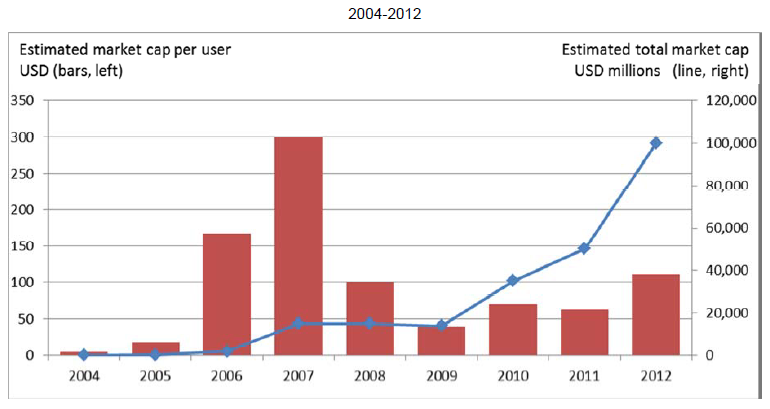
Il grafico che precede (Grafico 1) mostra la capitalizzazione di mercato di Facebook dal 2004 al 2012.
Nel 2012 Facebook entrava in borsa con un’offerta pubblica con quotazione iniziale di circa 100 miliardi, per una user base di circa 900 milioni di persone – un valore quindi di circa 111 dollari per ogni utente.
La compravendita di dati
Un altro modo per stimare il valore economico dei dati è acquisire direttamente informazioni sul mercato della compravendita di dati.
Si stima che esistano più di 4.000 data brokers al mondo, con alcuni “super data brokers” che guidano il mercato, come Acxiom, Oracle, Nielsen, Experian, o Salesforce. Solo Acxiom possiede 23.000 server, il cui unico scopo è acquisire e analizzare dati personali dei consumatori, attraverso circa 3.000 data points a persona.
Come è facile intuire, i dati personali valgono molto per questa industria, che nonostante sia molto recente, vale ormai più di 200 miliardi di dollari.
Un rapporto di maggio 2021 della Taskforce on Innovation, Growth and Regulatory Reform del Regno Unito stima che un singolo indirizzo e-mail possa valere fino a $89, e che i dati prodotti da una persona valgono sul mercato in media fra i $2.000 – $3.000.
Il business model è molto semplice: nella maggior parte dei casi i data broker vendono liste contenenti una serie di dati personali che raccolgono sia direttamente, che attraverso fonti terze.
Non sempre queste liste contengono dati immediatamente identificativi. Una grossa fetta dell’industria del data brokering riguarda infatti esclusivamente i dati di localizzazione, che sono comprati da altre aziende e poi usati per arricchire informazioni in loro possesso e aumentare il valore produttivo del loro patrimonio informativo.
Molti di questi giganti del data brokering hanno anche accordi specifici con i giganti del web, come Facebook o Google. Il risultato è un ecosistema di compravendita globale e su larghissima scala di dati personali.
Non tutti i data broker sono uguali. Alcuni, come Oracle, sono più orientati al mercato consumer, trattando dati che riguardano soprattutto abitudini d’acquisto, comportamenti online, e transazioni economiche. La compagnia afferma vendere in tutto il mondo i dati di più di 300 milioni di persone, con circa 30.000 attributi per ogni persona.
Altri, come Experian, sono invece famosi per trattare e vendere dati relativi all’affidabilità creditizia delle persone (il cosiddetto credit scoring).
Questi dati permettono alle aziende di diminuire il rischio di frodi o ridurre la rischiosità del portafoglio clienti, e sono sicuramente tra i più preziosi per il settore Business to Business, e in alcuni settori del Business to Consumer (banking, energy & utilities).
In Italia l’accesso a questi dati è regolato da leggi ad hoc che istituiscono e disciplinano i Sistemi Informativi Creditizi (SIC) e da uno specifico Codice di Condotta approvato dal Garante per la Protezione dei Dati, che prevede particolari tutele e garanzie per le persone.
I dati: l’oro del cybercrime
I dati sono una delle principali fonti di guadagno del cybercrimine. Il cybercrime è ormai una vera e propria industria, e gli attacchi sono ampiamente automatizzati e su larga scala, oltre ad essere sempre più frequenti e sofisticati.
Secondo alcuni studi recenti l’industria del cybercrime ha un ritorno economico di più di 1.5 trilioni di dollari all’anno.

Se confrontato con i 280 miliardi di fatturato annuali di Amazon (2019), è facile rendersi conto dell’incredibile portata di questa economia sommersa.
Le attività maggiormente remunerative per la cybercriminalità sono tre:
- Mercati online, con vendita di beni e servizi illegali
- Furto e vendita di segreti industriali, brevetti e proprietà intellettuale
- Furto e vendita di dati personali
In particolare, il mercato per la compravendita di dati personali sembra avere un valore che si aggira intorno ai 160 miliardi.
La fonte di questi guadagni incredibili sono le aziende, vittime spesso inconsapevoli di violazioni e furti di dati personali e preziose informazioni aziendali. Il 2020 è stato finora l’anno peggiore di sempre.
Secondo il Rapporto Clusit 2021 i cyberattacchi gravi sono aumentati del 20% tra il 2018 e il 2020, arrivando a 1.871 attacchi gravi nel 2020. In media, circa 156 attacchi gravi al mese.
Per fare un paragone, sarebbe come se nel nostro paese ogni mese ci fossero 156 rapine a mano armata in banca. Tra le categorie più colpite: pubblica amministrazione, sanità, ricerca, educazione, e servizi Cloud.
Il primato negativo della pubblica amministrazione per quanto riguarda il cybercrime non stupisce. Secondo un censimento fatto da AgID nel 2020 su un campione di 1252 data center usati dalla pubblica amministrazione, più di 1190 sono risultati inadeguati da un punto di vista della sicurezza. Il 13% di questi data center è stato realizzato prima del 1996.
Insieme al numero di violazioni di dati e cyberattacchi è aumentato anche il volume di dati venduti sul dark web. Ma come funziona il mercato illegale di dati e quanto valgono davvero questi dati?
Per quanto strano possa sembrare, la compravendita online di dati ottenuti illegalmente non è poi molto diversa dalla compravendita legale.
Oggi esistono veri e propri e-commerce dove i cybercriminali mettono in vetrina i dati rubati a persone e aziende. La lista di dati in vendita su questi mercati illegali è virtualmente infinita.
Per i servizi più evoluti sono previsti anche servizi di customer service e specifiche garanzie sulla bontà del dataset, esattamente come per qualsiasi altro data broker. In alcuni casi, ci sono perfino recensioni sull’affidabilità e professionalità del vendor.
Secondo il Dark Web Price Index 2021, elaborato da Privacy Affairs, si va dai dati più classici come email, carte di credito, documenti d’identità o account PayPal, fino ad arrivare ad account Netflix, crypto, o social networks.
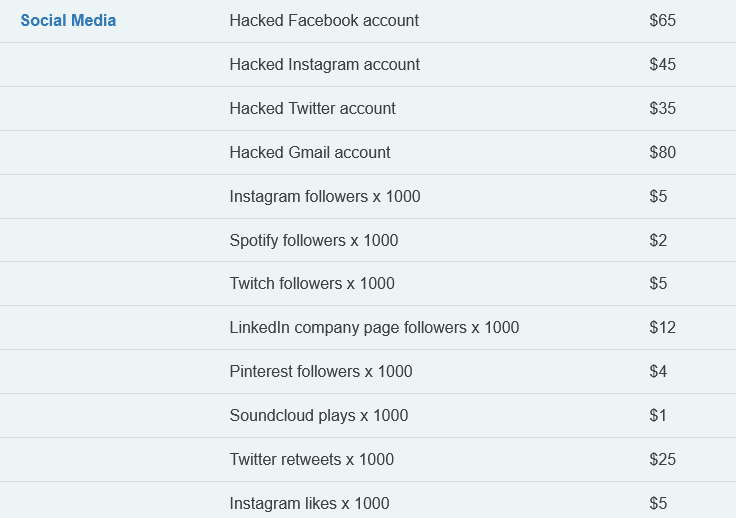
Una lista con più di 500.000 email sul mercato nero costa poco più di 40 dollari. Un account Facebook circa $65, contro i $45 di Instagram e $35 di Twitter. Le carte di credito costano invece pochissimo: una carta collegata a un conto con almeno $5.000 costa appena $24.
Tra i dati più costosi ci sono i passaporti, che arrivano a costare anche $6.500 l’uno. È probabile che inizieranno a circolare presto anche Green pass e dati relativi alle vaccinazioni COVID. Quanto potranno valere sul mercato nero?
Se da un lato ci sono i cybercriminali, dall’altro ci sono le aziende che ne subiscono le conseguenze.
Secondo le ultime stime, il cybercrime costa alle aziende circa 945 miliardi di dollari ogni anno a livello globale, a cui devono aggiungersi quasi altri 200 miliardi di investimenti in cybersicurezza.
Non tutto però è perduto. Le aziende europee hanno oggi a loro disposizione il GDPR, che esigendo elevati standard qualitativi per il trattamento dei dati contribuisce a rendere più efficienti i processi aziendali interni e a rendere più sicuro il patrimonio informativo.
Fonti:
Centre for Information Policy Leadership (2018) The Case for Accountability: How it Enables Effective Data Protection and Trust in the Digital Society.
Cisco (2021) Forged by the pandemic: The Age of Privacy, Data Privacy Benchmark Study.
Cisco (2020) From Privacy to Profit: Achieving Positive Returns on Privacy Investments, Cisco Data Privacy Benchmark Study 2020, Data Privacy January 2020.
Commissione Europea (2020) Strategia europea in materia di dati, sito ufficiale: https://ec.europa.eu/info/strategy/priorities-2019-2024/europe-fit-digital-age/european-data-strategy_it.
IBM Security (2021) Cost of a Data breach Report 2020.
Ker, D. and E. Mazzini (2020) Perspectives on the value of data and data flows, OECD Digital Economy Papers, No. 299, OECD Publishing, Paris, https://doi.org/10.1787/a2216bc1-en.
OECD (2013) Exploring the Economics of Personal Data: A Survey of Methodologies for Measuring Monetary Value, OECD Digital Economy Papers, No. 220, OECD Publishing, Paris, https://doi.org/10.1787/5k486qtxldmq-en.
Ponemon Institute LLC, IBM Security (2018) Cost of a Data Breach Study: Global Overview.
Solid, sito ufficiale: https://solid.mit.edu/.
Signal Foundation, sito ufficiale: https://signalfoundation.org/
Potrebbe interessarti anche

Data Center in Italia: Analisi delle Criticità tra Impatti Ambientali e Sovranità Digitale

Peter Thiel a Roma: tra conferenze religiose e affari con lo Stato italiano

Age Verification: Come siamo arrivati all’app UE?

Chatcontrol 1.0: cosa cambia dopo il voto europeo?

I minori nella società digitale: cosa sta succedendo in Europa?

Pratiche, alfabetizzazione e divari nell’AI generativa

Nordio, i “trojan diabolici” e le intercettazioni

Comunicato ufficiale sulla Riforma GDPR e Digital Omnibus
